Prompting Large Language Models as Explainable Metrics
Due to unforseen circumstances the test phase will be conducted on Codabench. For more information, please check our Google group and the submission instructions on the Codabench page.
Important Dates
All deadlines are 11.59 pm UTC -12h (“Anywhere on Earth”). The timeframe of the test phase may change.
- Share task announcement: August 02, 2023
- Dev phase: August 07, 2023
- Test phase:
September 18September 25, 2023 - System Submission Deadline:
September 23September 30, 2023 - System paper submission deadline:
October 5October 6, 2023 - System paper camera ready submission deadline: October 10, 2023
Updates
- October 6, 2023: Updated the citation for the shared task
- October 1, 2023: Added information on submitting to both tracks and added the Paper submission Link
- September 27, 2023: Addedd information on system papers that was announced earlier in our google group.
- September 25/26, 2023: The test phase has now started. Please view our announcements in the google group. Further details about the test phase can also be found on this page. Specifically, we also give brief example of the test sets.
- September 13, 2023: We have updated the schedule of the test phase and provided further new information in the google group.
- August 28, 2023: Expansion of model selection. Short update on tracks.
- August 24, 2023: The selection of further models is a bit delayed but will soon conclude.
- August 15, 2023: Adding additional examples, resources and information regarding teams on this page.
- August 11, 2023: Adding information about submission tracks (further may follow).
- August 08, 2023: Release of the CodaLab Dev Competition (the test will be published there later).
- August 07, 2023: Release of Github Page with Baselines and extended model list.
Overview
With groundbreaking innovations in unsupervised learning and scalable architectures the opportunities (but also risks) of automatically generating audio, images, video and text, seem overwhelming. Human evaluations of this content are costly and are often infeasible to collect. Thus, the need for automatic metrics that reliably judge the quality of generation systems and their outputs, is stronger than ever. Current state-of-the-art metrics for natural language generation (NLG) still do not match the performance of human experts. They are mostly based on black-box language models and usually return a single quality score (sentence-level), making it difficult to explain their internal decision process and their outputs [e.g. 14, 15].
The release of APIs to large language models (LLMs), like ChatGPT and the recent open-source availability of LLMs like LLaMA has led to a boost of research in NLP, including LLM-based metrics. Metrics like GEMBA [7] explore the prompting of ChatGPT and GPT4 to directly leverage them as metrics. Instructscore [12] goes in a different direction and finetunes a LLaMA model to predict a fine grained error diagnosis of machine translated content. We notice that current work (1) does not systematically evaluate the vast amount of possible prompts and prompting techniques for metric usage, including, for example, approaches that explain a task to a model or let the model explain a task itself, and (2) rarely evaluates the performance of recent open-source LLMs, while their usage is incredibly important to improve the reproducibility of metric research, compared to closed-source metrics.
This year’s Eval4NLP shared task, combines these two aspects. We provide a selection of open-source, pre-trained LLMs. The task is to develop strategies to extract scores from these LLM’s that grade machine translations and summaries. We will specifically focus on prompting techniques, therefore, fine-tuning of the LLM’s is not allowed.
Based on the submissions, we hope to explore and formalize prompting approaches for open-source LLM-based metrics and, with that, help to improve their correlation to human judgements. As many prompting techniques produce explanations as a side product we hope that this task will also lead to more explainable metrics. Also, we want to evaluate which of the selected open-source models provide the best capabilities as metrics, thus, as a base for fine-tuning.
Goals
The shared task has the following goals:Prompting strategies for LLM-based metrics: We want to explore which prompting strategies perform best for LLM-based metrics. E.g., few-shot prompting [1], where examples of other solutions are given in a prompt, chain-of-thought reasoning (CoT) [2], where the model is prompted to provide a multi-step explanation itself, or tree-of-thought prompting [3], where different explanation paths are considered, and the best is chosen. Also, automatic prompt generation might be considered [4]. Numerous other recent works explore further prompting strategies, some of which use multiple evaluation passes.
Score aggregation for LLM-based metrics: We also want to explore which strategies best aggregate the model scores from LLM-based metrics. E.g., scores might be extracted as the probability of a paraphrase being created [5, 6], or they could be extracted from LLM output directly [7].
Explainability for LLM-based metrics: We want to analyze whether the metrics that provide the best explanations (for example with CoT) will achieve the highest correlation to human judgements. We assume that this is the case, due to the human judgements being based on fine-grained evaluations themselves (e.g. MQM for machine translation). Metric explainability additionally could aid many more use-cases as discussed in [14, 15]. This goal is also in line with the Eval4NLP21 shared task [16], which explored the use of explainability techniques to compute word-level scores.
Task Description
The task will consist of building a reference-free metric for machine translation and/or summarization that predicts sentence-level quality scores constructed from fine-grained scores or error labels. Reference-free means that the metric rates the provided machine translation solely based on the provided source sentence/paragraph, without any additional, human written references. Further, we note that many open-source LLMs have mostly been trained on English data, adding further challenges to the reference-free setup.
To summarize, the task will be structured as follows:- We provide a list of allowed LLMs from Huggingface
- Participants should use prompting to use these LLMs as metrics for MT and summarization
- Fine-tuning of the selected model(s) is not allowed
- We will release baselines, which participants might build upon
- We will provide a CodaLab dashboard to compare participants' solutions to others
As of August 7, we have released the first baselines in the shared task github repositoryb>. This repository also contains "train" and dev data. The CodaLab dashboard for the dev sets is available here.
We will allow the following models from Huggingface:
- Guanaco-65B-GPTQ: A four-bit quantized version of Guanaco-65B by [11]. We choose this model as its training data is multilingual to some extent.
- Platypus2-70B-Instruct-GPTQ: A model by [17]. It shows strong performance on leaderboards. It is based on LLaMA2. We add it as a second big model besides Guanaco. We use a quantized version to make it runnable on more systems.
- WizardLM-13B-V1.1-GPTQ: A four-bit quantized version of WizardLM-13B-V1.1 by [13]. We choose this model due to its good performance on leaderboards. We are not using the verions based on LLaMA2 as it might have been trained on recent Wikipedia articles, which we will build our test sets on.
- Nous-Hermes-13b: A model by Nous Research. We choose this model due to its good performance on leaderboards.
- OpenOrca-Platypus2-13B: A model by [18, 20]. It shows strong performance on leaderboards for a 13B model and is based on LLaMA2.
- orca_mini_v3_7b: This model by [29, 20] is smaller than the others on this list and also performs well on LLM leaderboards. We include it to accommodate for less hardware availability.
Please run the quantized model with their default act.order files.
Scores of baselines with these models on the Dev set can be found on our CodaLab page. Basline scripts are available on our GitHub.
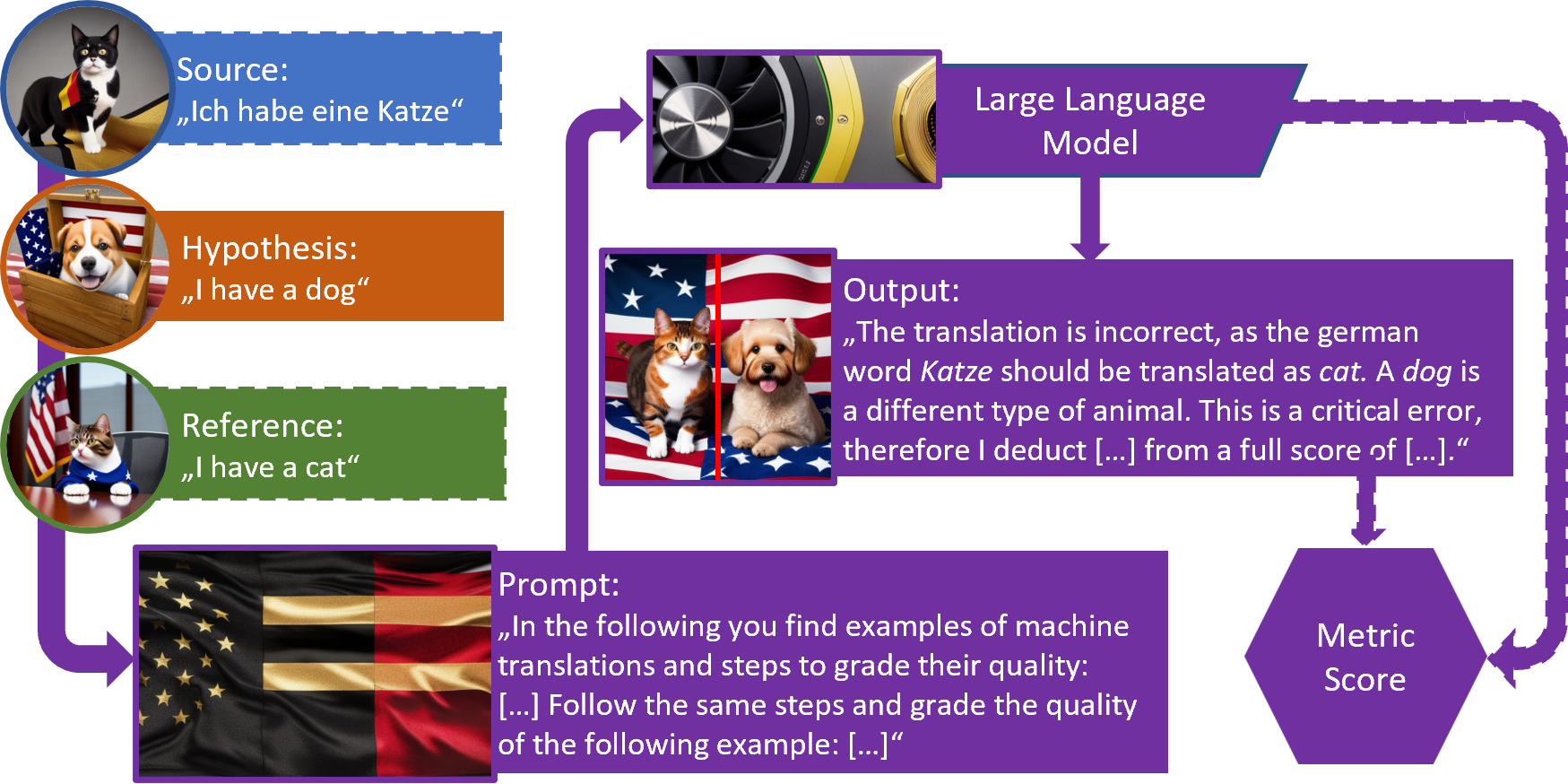
This image shows an example of prompting based metrics. The sentences that should be evaluated are wrapped into a prompt that is passed to a language model as an input. Then the model generates an output that contains a score, a score is constructed from the output or a score is constructed from other model states.
Teams
Participants of the shared task might either work on it alone or in a team. When participants are working in a team, they should only use one account for submissions on the test task. On the dev task, participants can submit with as many people and as often they like.
Tracks
We will offer two tracks based on the model sizes. One for models bigger than 25B parameters, one for smaller models. Participants that want to submit in both tracks (small and large models) can do so by sending us the second submission's Codabench ID via gmail before the end of the test phase. If you do so the other track's submission has still to be submitted to the leaderboard.
Another track looks at the explainability of the LLMs. This track can be tackled together with the others. Participants can provide newline separated files that can contain any types of explanations their models create as a byproduct of the grading process. We will evaluate the submissions in a human evaluation.
Data
The training and development data for this shared task are the MQM annotations of the WMT22 metrics shared task [8] for MT and the average of aspect based scores of SummEval [9] for summarization. We note that the human annotations of SummEval are not based on phrase level. Thus, our test data might be quite different. Also, we will generally evaluate in reference-free settings, i.e. MT metrics will take a source sentence and a translation as input and summarization metrics will take a document and its summary as an input.
As test data, we collected a new reference-free dataset with sentence/summary-level quality scores for MT and summarization. As source data, we leverage sentences and paragraphs collected from English Wikipedia pages created after 15.07.2023 (i.e. the LlAMA2 training cutoff). For MT, we follow the MQM annotation guidelines by [10] and those provided with the Google annotation tool Anthea. We provide the language pairs English-German, English-Chinese and English-Spanish.
Consider the following example: German source: "Ich habe einen Hund"; English translation: "I have a cat". The word cat should be translated as dog. In MQM annotation, this would be marked as a single major error. Scores are assigned based on error severity and count.
For summarization, we apply an approach that uses MQM annotations to analyze the readability of the source text. Further, this approach annotates the factuality (presence of facts) by mapping facts between source and reference text. Aditionally, we assess relevance by annotating each sentence in the source text with a relevance score. As for MT, we will construct paragraph level scores from this fine-grained annotation.
Consider the following example: Source: "I have a dog. It is small. I love it."; Summary: "I lve my big dog". In our annotation scheme, we would first assign relvance scores to each input sentence, i.e., should the fact represented in the sentence be part of the summary. Here, we could say that the first sentence is very relevant and the other two are of medium relevance. Second, we annotate the facts that occur in the summary and all hallucinated content. Third, we apply MQM annotation to flag grammatical and other errors in the summary. Finally, we use these properties in a heuristic to penalize summaries with a lot of errors and hallucinations and reward summarizes that include many relevant facts. The length of generated summaries was restricted for employed summarization models. In the case of the upper example the summary would contain one relevant and one medium fact, one hallucination and one spelling mistake.
To summarize, our test-phase scores are constructed from fine grained scores, so metrics that are built in a similar way (return and aggregate fine-grained scores) might achieve better performance.
Evaluation
We follow the evaluation protocol of the WMT22 metrics shared task and evaluate with segment-level Kendall correlation. The shared task winner will be the systems that achieve the significantly highest correlation on the test set. It will be possible to only participate for MT or summarization.
We also plan to perform a human evaluation of the explainability of each system submission as a separate track. To do so, participants can provide separate files with any kind of explanations their model produces as byproduct. These explanations should be separated by newlines.
Baselines
As of August 7, we have released the first baselines in the shared task github repository. This repository also contains "train" and dev data.
System Papers
System Paper: Participants of the shared task that want to be eligible to win, to be listed in our shared task summary paper and to describe their system in the shared task’s proceedings are required to submit a system paper. These papers may be short papers (max. 4 pages) and long papers (max. 8 pages), though shorter submissions are also allowed. We recommend starting to write this paper as soon as possible, as there will not be much time left after the test phase (5 days + 5 days to camera ready)! Please follow the ACL ARR formatting requirements, using the official templates. Paper submission will be via OpenReview here
.In the system paper, you may cite the shared task as follows:
@inproceedings{
eval4nlp23,
title={The Eval4NLP 2023 Shared Task on Prompting Large Language Models as Explainable Metrics},
author={Christoph Leiter and Juri Opitz and Daniel Deutsch and Yang Gao and Andreas Rücklé and Rotem Dror and Steffen Eger},
booktitle={Proceedings of the 4th Workshop on Evaluation and Comparison for NLP systems},
year={2023},
}Examples
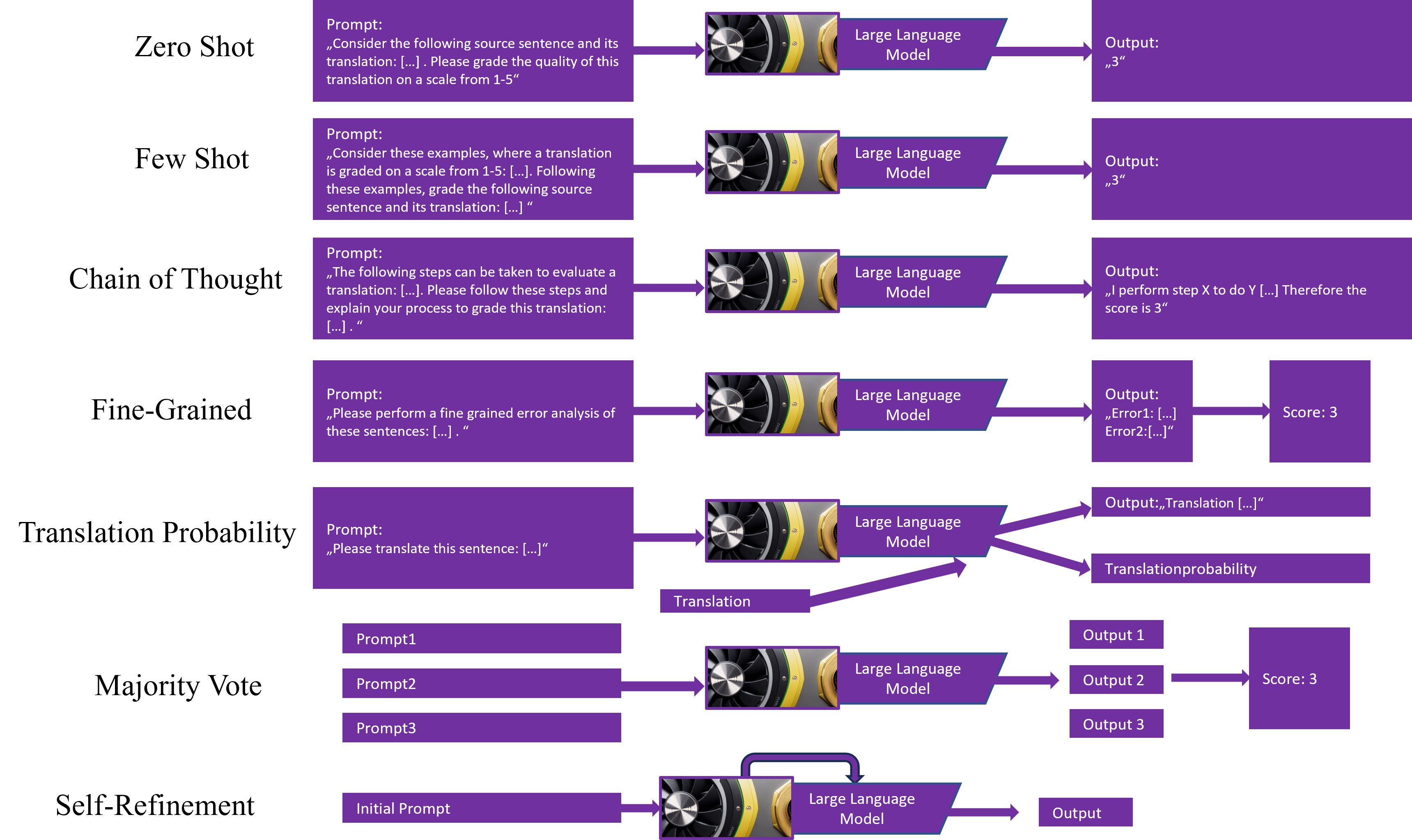
The following image shows exemplary prompting setups that might or might not prove useful in the shared task. Some of them will likely produce explanations of some sort while others will only return a score. A number of prompts have already been tested in recent works. E.g. [7] use a zero-shot setting, [6] use a translation probability setting and [12] aggregate sentence-level scores from a fine-grained error taxonomy (though they fine-tune their model).
Submission
The Codabench dashboard for the test phase is available here The data can be found in our github repository. Submissions will require a file with one score per line, matching the rows of the tsv files provided in our repository. Final submissions will require further details, such as more detailed system descriptions, prompts and (if any) explanations. Details on the test set submissions can be found on the Codabench submission site. The explanations are planned to be evaluated by humans.
Recommended Resources
Resources related to prompting:
- promptingguide.ai/
- Awesome-Prompt-Engineering
- awesome-awesome-prompts
- awesome-gpt-prompt-engineering
- ICL_PaperList
- prompt-in-context-learning
- Kocmi and Federmann, Large Language Models Are State-of-the-Art Evaluators of Translation Quality. arxiv-eprint: 2302.14520. 2023.
- Chiang and Lee, Can Large Language Models Be an Alternative to Human Evaluations?. In: ACL 2023.
- Xu et al., INSTRUCTSCORE: Towards Explainable Text Generation Evaluation with Automatic Feedback. arxiv-eprint: 2305.14282. 2023.
- Liu et al., G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. arxiv-eprint: 2303.16634. 2023.
- Fu, et al.(2023). GPTScore: Evaluate as You Desire. arxiv-eprint: 2302.04166.
References
[1] Brown et al., Language Models are Few-Shot Learners. In: NeurIPS [2] Wei et al., Chain of Thought Prompting Elicits Reasoning in Large Language Models. In: Advances in Neural Information Processing Systems [3] Yao et al., Tree of Thoughts: Deliberate Problem Solving with Large Language Models. ArXiv: 2305.10601 [4] Zhou et al., Large Language Models are Human-Level Prompt Engineers. In: ICLR 2023 Poster [5] Thompson and Post, Automatic Machine Translation Evaluation in Many Languages via Zero-Shot Paraphrasing. In: EMNLP2020 [6] Yuan et al., BARTScore: Evaluating Generated Text as Text Generation. In: Advances in Neural Information Processing Systems (Vol. 34, pp. 27263–27277) [7] Kocmi and Federmann, Large Language Models Are State-of-the-Art Evaluators of Translation Quality. ArXiv: 2302.14520 [8] Freitag et al., Results of WMT22 Metrics Shared Task: Stop Using BLEU -- Neural Metrics Are Better and More Robust. In: WMT22 [9] Fabbri et al., SummEval: Re-evaluating Summarization Evaluation. In: Transactions of the Association for Computational Linguistics [10] Freitag et al., Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation. In: Transactions of the Association for Computational Linguistics [11] Dettmers et al., QLoRA: Efficient Finetuning of Quantized LLMs. Arxiv: 2305.14314 [12] Xu et al., INSTRUCTSCORE: Towards Explainable Text Generation Evaluation with Automatic Feedback. arxiv-eprint: 2305.14282. 2023. [13] Xu et al., WizardLM: Empowering Large Language Models to Follow Complex Instructions, Arxiv: 2304.12244 [14] Leiter et al., Towards Explainable Evaluation Metrics for Natural Language Generation, Arxiv: 2203.11131 [15] Leiter et al., Towards Explainable Evaluation Metrics for Machine Translation, Arxiv: 2306.13041 [16] Fomicheva et al., The Eval4NLP Shared Task on Explainable Quality Estimation: Overview and Results, In: Eval4NLP21 [17] Lee et al., Platypus: Quick, Cheap, and Powerful Refinement of LLMs, Arxiv:2308.07317 [18] Lee et al., OpenOrcaPlatypus: Llama2-13B Model Instruct-tuned on Filtered OpenOrcaV1 GPT-4 Dataset and Merged with divergent STEM and Logic Dataset Model, Huggingface [19] Mathur, orca_mini_v3_7b: An explain tuned Llama2-7b model, Huggingface [20] Mukherjee et al., Orca: Progressive Learning from Complex Explanation Traces of GPT-4, Arxiv: 2306.02707Contact Information
- Please join our Google Group for posting questions related to the shared task.
- If you want to contact the organizers privately, please send an email to eval4nlp@gmail.com.